Why we sold intermix.io to private equity in a shifting market
On April 1st, 2020 we completed the acquisition of intermix.io by Xplenty, a data integration (“ETL”) firm. The deal was financed by Xenon Partners, a private equity firm focused on buying SaaS companies.
In this post, I’m sharing a note that I sent to our angel investors late January, as we had started the process to sell the company, explaining the reason for the exit, and the events leading up to that.

Of course, Covid-19 played a key role in the decision to sell. In early February, venture funding dried up within a matter of days, and we were in the middle of a product overhaul, with cash in the bank until August 2020. Hope that Covid would go away and things would go back to normal wasn’t a strategy. It’s June 2020 now, and that decision has proven right.
This post is more about the mechanics of markets and ever-evolving product-market-fit. I’ll keep it high level without going too deep into the tech, but it’s helpful to have a basic understanding of what we built. So before the actual letter, I’ll go a bit into our funding and product history.
Our story
We raised our seed round in February 2018 (TechCrunch covered the round in April 2018), as an analytics service for data products.
Think of data products as the output of a data assembly line that collects raw data from a bunch of disparate sources. Your SaaS systems, your production databases, 3rd party data sources, etc. All that brought to together, in a nice clean format, so you can slice and dice your data in any imaginable way. It’s so powerful, that more and more people got access to that data, via fancy self-service analytics dashboards in e.g. Looker, Tableau and Metabase.
Running lots and lots of queries puts a lot of pressure on data infrastructure. We had built a dashboard that gave analytics engineers a visual representation of the complex data flows across that assembly line. Our dashboard was a nice way to travel back in time (days, months and even years) and ask “what happened with our data?”.
With a few clicks in that dashboard, engineers can quickly drill down into the root cause of a stuck query or a table that’s suddenly exploding in size. Or simply just poke around and wonder “well who’s been querying our data?”.
Our customer Udemy wrote about it here on Medium:
Cloud warehouses
The key “work station” of the assembly line is a cloud-based data warehouse, like Amazon Redshift, Google BigQuery or Snowflake. The data warehouse is where all the joining and transforming of data happens. Understanding data warehouses is a key part for understanding our story.
Cloud warehouses are different from traditional data warehouse appliances, where the database is coupled with the hardware. With an appliance, when you run out of capacity, you need to order another appliance, install it, test it, put a back-up and disaster recovery process in place, etc. That’s a time-consuming and expensive process. Classic appliance vendors are Teradata, HP (Vertica), IBM and of course Oracle.
Compare that with a cloud warehouse, where you provision new capacity within seconds with a click in your cloud console. All the hard stuff like disaster recovery, redundancy, etc. — the cloud platform takes care of it, and it’s all baked into a single price. “Simplicity” is the key value proposition.
Add to that that cloud warehouses cost up 20x less and run queries 100x (yes, hundred times!) times faster than appliances, with a starting price of ~$0.25 per hour vs. carving out millions for an appliance before even running a single query, and it won’t surprise you that cloud warehouses took the analytics world by storm.
AWS recognized the opportunity and launched Amazon Redshift in 2012. Redshift was the first cloud warehouse in the market. Building a data warehouse is a massive undertaking and takes years and years of R&D, but AWS didn’t want to wait. So they went out and bought the technology.
AWS’s innovation was to “cloudify” the delivery of the warehouse in a SaaS model as part of the AWS product portfolio.
That’s actually very hard to do, but AWS is really good at providing any technology as a cloud service. With Redshift, in very simple terms, they put a database server into the cloud, and made it available at the proverbial push of a button.
The rise of cloud warehouses was the “why now?” for intermix.io
Amazon Redshift and our product
We had started intermix.io as a corporate entity in February 2016. At that time, we had an idea and some promising feedback on our idea from data engineering teams here in San Francisco. So we started cold outreach, listened to customers, built mock-ups based on their feedback, launched an alpha version, iterated on that, got a private beta. That all happend while bootstrapping.
We collected an small angel round ($650K) in November 2016 on a beta version, with some great initial customer logos like Udemy, Postmates and WeWork.
When we started, we supported Amazon Redshift as the clear market leader. DB-Engines has a popularity ranking of every database under the sun. This is popularity, not market share — but still a good proxy. In the selection below, you can see a selection of data warehouses, incl. the two major appliances with Teradata and Vertica. Note that it’s a logarithmic chart.
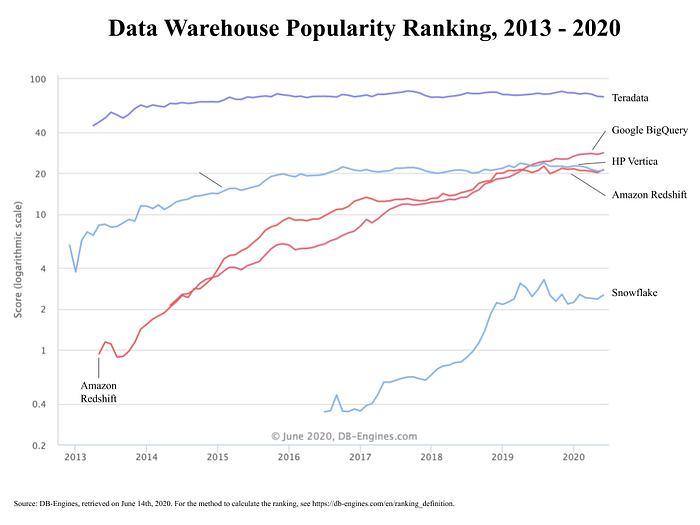
In 2016, there were only two choices in the cloud warehouse market:
- Google BigQuery
- Amazon Redshift
With AWS about 10x the size of GCP at the time, it was a no-brainer to go with Redshift. Walk into any start-up in SF back then, and they were using Redshift. As far as we could tell, everybody was using Redshift. Redshift was the only game in town.
We had always planned to support other cloud warehouses, but with a limited budget and engineering resources, we had to pick one, and we picked Redshift. As it happens, over time we built more features, and slowly but steadily we became “the Redshift dashboard that I’ve always wanted” in the language of our customers.
Enter Snowflake Computing
You can see on the popularity ranking how a small company called “Snowflake” came onto the radar in late 2016. We’ll go into Snowflake a bit more in detail below.
The tl;dr for Snowflake is that it’s founded by a ex-Oracle engineers with over 120 patents in data warehouses, data architecture, query optimization, etc. They also saw the future in the cloud, and left Oracle frustrated by its focus on the old appliance world. Oracle was caught in the classic innovator’s dilemma.
Unlike AWS though, the Snowflake founders went down the path of building the technology from the ground up. They had different vision for the tech. It shouldn’t be “old” tech delivered via a “new” model. “Old” refers to the existing server-centric paradigm where resources are still shared.
Rather, they wanted the warehouse to operating in a “new”, emerging paradigm called “serverless”, where the main resource of a cloud warehouse (compute, storage) are decoupled.
Here’s how Snowflake describes their product:
Snowflake Warehouse is a single integrated system with fully independent scaling for compute, storage and services. Unlike shared-storage architectures that tie storage and compute together, Snowflake enables automatic scaling of storage, analytics, or workgroup resources for any job, instantly and easily.
It’s a very elegant model, and we’ll see below how the analytics ecosystem eventually decided that it’s the future of how they want to operate with data.
Let’s get into the details
With the background above, you should have enough details on the history of the market intermix.io operates in — cloud warehouses.
So let’s go into the letter that I sent. I slightly tweaked it for better understanding, but it’s 99% the original version. I sent the letter with a personal note to each invididual angel, not in a mass email.
Keep in mind that many of the angels invested based on knowing me, not necessarily based on knowing the market. So I went back in time a bit and re-iterated some of the recent technology trends, competitive dynamics, etc.
As a founder, the least you can do for your investors is provide a thorough write-up of what happened, and why.
But here we go, the letter!
The letter
Adding a lot of context here, maybe too much, but I hope it’s helpful. For you as an investor, I hope there are some lessons learned in here for your other start-ups.
After our seed, we were on a good growth trajectory, with $500K in ARR, and growing, the magic $1M mark to get to a Series A was in reach. We had great customer logos like Plaid, Medium and ThredUp. We thought we had product/ market fit for our Redshift product.
But around Q3/Q4 2018, things suddenly flattened out. Less inbound leads, less questions on Quora, less Redshift-centric technical blog posts from the ecosystem. Less of everything. Just disparate signals, but in hindsight they all added up to a major shift.
the tl;dr:
- We were operating in a growing market (cloud warehouses), but in a shrinking segment (performance) within that market.
- The reason for shrinking was a paradigm shift in technology, from “server-based” (old) to “serverless” computing (new), in which the need for “performance” went away.
- We supported the old model, and therefore our market broke away within a couple of quarters, and we didn’t react fast enough.
The best representatives are Amazon Redshift for the “old” paradigm and Snowflake for the “new” paradigm. Snowflake is another cloud warehouse.
Our mistake was that we addressed that paradigm change too late.
So what happened?
Snowflake was on the rise. And Snowflake’s rise really took the wind out of our sails. We addressed that challenge (and opportunity, to be a player in their ecosystem) too late.
That’s where we failed. Also, in Dec 2018, one of our flagship customers (WeWork) told us they’d migrate to Snowflake. In hindsight, that should have been THE signal.
Snowflake addressed our core segment — SMBs that use Redshift and were unhappy due to performance issues. Snowflake offered a better product that made the migration from Redshift (the market leader by 10x in terms of number of customers) worthwhile. And so our addressable market cratered within just 2 quarters.
So I think it’s helpful to cover a few basics on cloud warehouse tech and economics, to shed more background on why it all happened.
Cloud Warehouse Tech & Economics
In a server-based model, you have a finite unit with a pre-determined amount of CPU, memory and storage. They scale together — even though you only may need more of just one, you’ll have to add one more server if you run out of just one resource. So you run into a lot of bottlenecks all the time, and when that happens, unless you add more capacity, your database goes down.
The upside is that it’s very predictable in cost — you only spend more if you decide to add a server, and that’s a trade-off decision you can make. Therefore, performance tuning makes sense — your database doesn’t go down, you can squeeze out more ROI out of your investment and delay adding servers (which is $$$).
Now compare that with a serverless model like Snowflake. Snowflake’s innovation was to separate the resources from each other, i.e. “separation of storage and compute”. You can scale resources independently from each other, which makes it a very efficient model, for a number of reasons.
- First, you don’t encounter any bottlenecks anymore, because the system automatically scales either resource. So no more fire drills.
- Second, it’s also easier to manage, because a serverless system like Snowflake just adds those resources on the fly, as needed, aka “auto-scaling”.
- Third, unlike in a server-based model, there is no more downtime because you need to add a node to your warehouse, aka “re-sizing the warehouse”. That downtime gets longer the bigger your warehouse is.
The term for that is “zero admin”, and it means just that — there’s zero admin involved, it just works! The need for performance tuning is much smaller in a serverless model and shifts away from managing the resource (the server / nodes) to managing the users and their queries that drive resource usage. And Snowflake really nailed that technology.
[Note: AWS has and is fixing a lot of these gaps, but that just doesn’t happen overnight.]
But Silicon Valley is littered with great tech that never made it, so what’s so special about Snowflake?
What’s Snowflake?
Snowflake is another cloud warehouse, started by ex-Oracle data warehouse engineers in 2012 by Benoit Dageville, Thierry Cruanes and Marcin Zukowski. It took them some three years to get to GA (“general availability”) and commercialize their software.
On June 23rd 2015, Snowflake announced GA.
And that was really only the first version. It’s expensive and takes time to build a new database. But once in GA, they were ready to roll up the market from behind and keep adding functionality to a new paradigm.
Growth really kicked in around late 2018, with adoption among start-ups / SMBs. Fueled by over a billion in venture capital, with companies like Sutter Hill Ventures and Sequoia who are in it for the long term, Snowflake went after the greenfield opportunity and the easy migrations (SMBs) first, building huge momentum.
Snowflake’s Momentum — Redshift’s Loss
Redshift was the clear market leader in terms of footprint (~10x the size). And when you’re already running on AWS, it’s an easy step to just spin up a Redshift cluster, vs. going through the procurement process and security vetting for an entirely new vendor. That’s a massive pain, not to mention the even bigger PIA of migrating a database.
Yet customer went through that pain of migrating. Why? I think it comes down to three reasons:
1. Technology
2. Marketing
3. Distribution
Technology
I already covered how Snowflake is “zero admin”. Our customers who migrated called it “pure magic”. Other advantages are native support for uses cases like JSON format and secure data sharing. Data teams really wanted those use cases.
But let’s focus on the autoscaling part that comes with serverless. The irony is that the serverless model can be much more expensive than the server-based model. Sometimes up to 3–4x for the same workloads.
Turns out data teams are willing to trade that higher spend for not having to worry about managing their warehouse infrastructure.
We had customers like WeWork whose spend on Snowflake was 2x of what they had previously spent on Redshift and intermix.io combined, and they were just fine with it. [Note: the cost for our subscription is about 10–15% of a customer’s Redshift spend.]
You could argue that AWS fell asleep at the wheel. When we talked to them in our early days, AWS mentioned how they were delivering a massive business with a small team. I darkly remember that a LinkedIn search in 2016 produced some 30 FTEs working on Redshift at AWS.
They were able to do that because they had acquired the underlying tech for Redshift in 2010, from a company called “ParAccel”.
But now compare that to Snowflake. Early 2018 Snowflake had already scaled to some 100+ database engineers, and a total headcount of 430 FTE. Fast forward to today [February 2020], and Snowflake has over 1,700 employees, of which about ~500 FTEs work in engineering and product. The rest is a formidable salesforce, led by an even more formidable CEO with Frank Slootman.
Just check out the headcount growth on LinkedIn.
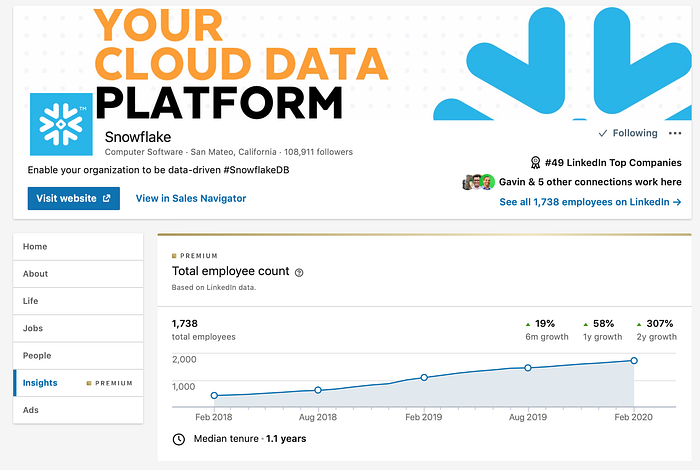
Based on LinkedIn, the whole Redshift team today [February 2020] has around 300 people working across engineering and product management. There’s a Redshift-specific business development team of about 30 people. So round numbers, we’re talking ~1,700 (Snowflake) vs. ~330 (Redshift) FTEs.
AWS brought a knife to a gunfight. While Andy Jassy has now made it a top priority to catch up, it will be a long journey.
Marketing
If you’ve ever worked with AWS, then you know that their sales reps pretty much go in with a “builder” story, flanked by a solution engineer who can tie the different pieces together. It’s really a Candyland of services — “here’s this, here’s that! Do a 3-year commitment, and we’ll give you a 40% discount.”
Snowflake on the other hand pitched a “promised land” of easy data sharing, and productive analytics.
You may have seen their billboards if you’ve driven on 101, or on 80 going on the Bay Bridge.
You can see all the different “Snowboards” here:
https://www.snowflake.com/snowboards/
It’s a true brand in the making. As you sift through the billboards, you’ll see that Snowflake captured the Zeitgeist with every new Snowboard.
Consider that the billboards started in 2017, when “data” was the hottest thing since sliced bread. Every damn start-up in the Bay Area suddenly was “based on AI”, “leveraging ML” and of course “data-driven”.
Each day, some 250,000+ cars drive along on 101 and the Bay Bridge. So you can imagine a scenario where product, sales and finance show up in engineering and ask “hey, are we using Snowflake?”. Frequently enough that any data engineering team would look into “what the hell is this Snowflake thing??”
I’ve also looked at Snowflake’s ABM (account-based marketing) program in detail.
Below a couple of examples from re-targeting ads Snowflake is running. Clicking on these ads leads to the company-specific landing pages. [and as of June 2020, these campaigns are still running!]

I couldn’t resist but going deep into those ABM operations, simply to understand how exactly they did it. You’d be amazed what you can find via publicly available materials, ping me if you care to know the details.
Either way, Snowflake supported their marketing with customer stories.
The difference is that they had their customers tell the story.
Yes, Snowflake has tons of customer case studies on their website.
But it’s much more powerful when the customer is the one telling the story, the actual engineer, without the marketing speak, just with the cold hard facts.
Here’s one example from Instacart, on Medium:
Just search for “snowflake migration” on Medium, and you’ll see what I mean. More stories like the one by Instacart. And of course, once they had brand names as customers, those brand names also appeared on the Snowboards.

On the web, there are dozens of other stories on the web on how companies migrated from Redshift to Snowflake and lived happily ever after, incl. with press coverage from paid media outlets like Computer World.
Go-to-market
I covered above how Snowflake hired a formidable sales force. But that only scales linearly and doesn’t explain their exponential growth. For a while, I couldn’t put my finger on it, and so looked at their billing and distribution model.
Snowflake has a usage-based billing model. But as I mentioned, in the serverless model, that can cost you 2–3x more than in the server-based model.
So how does Snowflake invoice? Snowflake is an official AWS partner. Turns out they do a lot of billing through the AWS Marketplace, and the amount you pay for Snowflake gets buried in the AWS bill, and also counts towards any commitment the customer made to AWS. I guess you call that “co-opetition”.
Snowflake Marketplace Listing: https://aws.amazon.com/marketplace/pp/B01MTL0TYF
Check the 257 (at the time of this email) reviews ….
Snowflake announced availability via the AWS Marketplace in November 2017. In this context, you have to know that AWS starting in 2018 really doubled down on driving sales through the Marketplace.
They assigned aggressive Marketplace quotas to their sales reps. The traditional way that’s done is by selling an enterprise discount program, with one massive lumpsum payment, some spend assigned to services sold by partners via the Marketplace.
And that’s where it gets crazy.
The AWS sales reps pretty quickly figured out three things:
- More spend! Because of Snowflakes’ billing model and the serverless approach, customers would spend 2–3x more on their data warehouse.
- Happy customers! Despite higher spend, customers were happy now because they didn’t have to deal with Redshift performance issues anymore, and they stopped complaining to the reps.
- Hit my (Marketplace) quota! Spend on Snowflake would go through the AWS Marketplace, which would contribute to the reps (Marketplace) quota. The lost revenue from Redshift sales that counted towards their direct quote was more than made up by general growth in AWS spend and the higher spend on Snowflake.
So what do you think the AWS Sales Reps did?
They started recommending and selling Snowflake to their customers. “It’s one of our partners, and we recommend what’s best for our customers.”
And just like that, Snowflake 10x-ed the size of their sales force, at the cost of paying AWS 9% of their top line sales through the AWS Marketplace.
You really can’t make this up….
In short, Snowflake had a vision for what customers wanted, built a differentiated technology, told a story around it, and nailed the distribution model.
Back to our story
And so here we were at the end of Q2 2019, finally understanding why our market was collapsing. We had to do something. So far, we had built new functionality, changed pricing, gave discounts — nothing had worked.
But at least now we knew why.
In Q3, I lined up our best customers for interviews, and also looked at our product usage data.

We learned three things:
- Customers bought our software, but really they bought us because of our Redshift expertise and the ability to fall back on us for advice. They looked at us as a consulting partner. Clearly that’s not good…
- Product engagement was centered around two specific features (Search / Discover, and Query Insights) — these were non-Redshift-specific features, and customers cared less about our opinionated Redshift-specific features.
- There wasn’t THE killer use case — instead, if you talked to ten different customers, you’d get ten slightly different use cases. Customers asked for the ability to reflect those use cases in the product. They wanted more flexibility / customization.
We also went back to the customers who had migrated to Snowflake. They all still loved us, but they loved Snowflake more. At least they told us that they wanted an “intermix.io for Snowflake”, again with a slight variance in use cases.
We wanted to have something ready for AWS Reinvent in early December. So after the interviews, and looking at the data, within eight weeks we built a new product that essentially turned the existing philosophy upside down.
Huge shoutout to my co-founder Paul and our engineering team with Erika, Christina, Chris, Stefan and Vasi. They turned around on a dime, built and shipped a new product from scratch to GA in a matter of a few weeks. I’ve never seen a team build product that fast. It was nothing but amazing to watch them go to work. Working with them has been one of the greatest privileges in my career.
In December, we launched our new product / messaging (“analytics for data products”), to move away from an opinionated dashboard on top of Redshift, to a product that works horizontally across all warehouses. We also started working on an actual alpha version of Snowflake, and were in close communication with Snowflake to launch in their marketplace.
The new product was built based on the customer feedback that we collected in Q3. We built a product that they can customize for their specific use case. You can see the major use cases on our website:
[in case that page will go down at some point in the future, here’s a full screenshot on Google Drive]
On the marketing side, to drive demand for the new product, in October we had started to build a Slack Community for Analytics Engineers. That community actually took off, with over 600 members now [early February 2020], and 25% DAUs. We also hosted “office hours” with the Redshift team on that channel, which really drove up engagement. We established ourselves as an authority at least in that market.
And then plan was to repeat that playbook for Snowflake. See our post on how we built our Slack Community:
In short, within 8 weeks, we changed product, pricing, website, messaging and built a community. We turned around on a dime. In late December, we launched the new product, and migrated customers over.
The early results of the new product were promising. However, because it was much less feature rich, and the consulting part went away — some of our contract sizes dropped at renewal, and we also lost a few customers. In short, the curve you want to show in your fundraising deck was heading the wrong direction.
Yes, we had an explanation for why, and a recipe for what do going forward. But at that point, with some $400K in ARR, a lower price point, and a yet-to-be-created top of the funnel for a new category — we were an early seed stage company again, not a Series A company.
And that’s why early January we started to engage in conversations with potential buyers, just to have a fall back, which takes us back to the beginning of my email.
[Note — thanks goodness we did that because Covid came at us like a ton of bricks at the end of January…]
What could we have done differently?
In hindsight, you can argue that we maybe should have never started the company. The clock for the server-based model was already ticking.
But we did start it, and with the early traction we had, with the customers that came on board — we were convinced that we had it figured out. But really, some of those customers were false positives. Many bought us mainly for the advice they got from us — less for the product.
Hindsight is 20/20 as they say, but a few things that I’d do differently if we were to do it all over again.
First, we should have gone straight to customizable dashboards for uses cases that worked cross-warehouse, and align us with growth / revenue initiatives, so we wouldn’t be perceived as a tax on the existing warehouse.
We assumed that engineers were ok with doing performance tuning of their databases and queries. That’s a common concept for bespoke applications, and the APM market with e.g. New Relic and Datadog.
Our product delivered that.
In fact, we do still today have engaged users. One of our customers, the CTO of a unicorn retail start-up, even said that he wanted to put money into our next round, because we give his data team so much leverage. He told me that in December!
But it turns out that the wider data / analytics engineering community does not want to have to tune their databases at all. They do not want to worry about it all, and just have the database itself do the job. And they don’t want to buy an add-on product — they want that functionality as part of the database.
Second, we should have aligned ourselves with the strength of cloud warehouse and Redshift in particular, and show “value by addition”. That’s what we do with our new product today.
Early days, during our beta phase, we focused on the negative story. “No more slow Redshift” was the promise on our website. That’s because performance problems caused slow queries and slow dashboards, and from customer interviews we always heard the phase “Redshift is slow”.
Yes, that promise worked. Hit the nail on its head, and we were signing up new customers with that promise. But it was “value by subtraction”. We rode on Redshift’s weaknesses. Nobody wants to use a product that has perceived weaknesses. We were basically a tax on the database to make it work.
Third, we should have engaged with the Redshift team much sooner for an acquisition. Our “old” product would have helped retain their users. Instead, we went the partner route — but that wasn’t successful because the AWS sales reps were promoting Snowflake.
[Note: AWS ended up buying another Redshift dashboard called “Datarow”, which is more focused on the need of analysts who write SQL.]
In closing
This email is already way too long, but I hope it provides some insight on how much uncertainty and volatility there can be, and how fast a market can turn against a start-up. We tried, but after four years, it’s time to move on.
I’ll keep you posted as we go through this phase.
Meanwhile — thank you so much for your early support!
Lars
Aftermath
Alright, that was the letter.
Laying out the whole process of selling the company is material for another blog post. Once we had a term sheet, it was three weeks until closure. That’s because Xenon is a professional buyer, and because our house was in order — tech, legal, compliance, IP, etc.
We had pristine operations, and the entire set of documents that Xenon had requested as part of the typical M&A due diligence was in the data room in less than 24 hours. Xenon told us they had never seen a company turn all data requests around that fast, ever. Not even close.
Sidenote — I can only recommend working with Xenon, they are fantastic people and deliver on their promises. Working with their team was nothing but a pleasure throughout the process.
Lessons learned
I don’t mean to blame our failure to raise a Series A on Snowflake or Covid. That’s on us. Like any start-up, we had our share of execution issues. But from how the whole story played out in our market, I have three major take-aways.
- Distribution beats product. There’s a saying that first time founders worry about product, second time founders worry about distribution. So true. Yes, there’s product-market fit, but it’s a theoretical concept and a moving target at best. If you’re one of two competitors, and your competitor has the better product, but you have better distribution, you win. Excellent distribution eats an amazing product for breakfast. If you have both excellent distribution and an amazing product, you will blow the doors off your market.
- Big markets forgive big mistakes. Everybody has execution issues. Everybody. But execution issues don’t matter as much if you’re in a massive, fast-growing market. Of course, you can’t screw up all the time. But hiccups, even major ones, are irrelevant if everything around you is big and growing. Just as an example, think about all the negative press Instacart, Robin Hood and Uber have received, for their various SNAFUs. Labor issues, HR violations, sexual harassment, death, product failures, day-long outages, lawsuits, etc. — you name it. Yet here we are, and people are shopping on Instacart, day-trading stocks on Robin Hood, and riding with a mask in an Uber. Markets are brutal, so pick a big one, or at least one that you think will be big.
- Value propositions that facilitate faster growth will always beat value propositions that deliver lower cost. No matter how much people love your product — if it’s considered a necessary evil and a tax, they will jump ship at the first occasion when there’s an alternative, no matter how cheap your product is, and even if the alternative means spending more overall. If people have a choice between a product that raises top-line growth by 5%, and a product that cuts their cost by 50% — they will go with the top-line growth product. The only exception here are step changes, i.e. 10x cheaper and 10x better. In the absence of step changes — everybody likes to grow, but nobody likes to cut costs. It’s human nature.
If these three major take-aways sound familiar, that’s because you’ll have heard about them elsewhere in a similar fashion. I’ve found them to be true, and I learned those lessons the hard way. And so I hope this post gives you a little edge for whatever is next for you.
For me — I’m more active in angel investing than ever. So shoot me a note on LinkedIn if you’re fundraising and thinking about your distribution strategy.
I’m happy to help.
I also publish a weekly newsletter “Finding Distribution” on Substack. Click the link below to subscribe:
